Hi, I’m using a set of TaskPaper files to organize sets of hashtags, and I’m wondering if anyone could help me with a script (or two scripts) for (1) removing all underscores (2) adding underscores (preferable just for second level items) wherever there’s a space separating words/text.
Although not as easy, you can use the Find and Replace command for that too.
Type a space in the Find field.
Type a underscore in the Replace with field.
Then use the Next button to skip through spaces that you don’t want to replace. When you get to a space that you want to replace, use the Replace or Replace & Find button.
So…I’ve been using the Find & Replace approach, and it has generally worked fine, but…I’m not having to switch back and forth between finding & replacing multiple formatting.
Is there a simple script or approach in AppleScript or Keyboard Maestro that would enable me to do this? Thanks again!
Hi @printer printer. I have seen similar things to what you have requested done with RegEx. You will have to come up with the RegEx (expression) that accomplishes what you want. Then you can run that many different ways.
I am not sure if there is a forum for RegEx experts that can help you come up with that first. Maybe it is a question for StackExchange. You will have to define specifically what you want so they understand your request. I think that there are a couple of people in this forum that are very fluent in RegEx, but I haven’t seen them in a while. @mattgemmell is the one that comes to my mind.
My understanding is that you will need two RegEx
One that selects all the hashtags that have underscores in them and then selects the underscores in that hash. You can then remove them easily
One that selects all the hashtags that have spaces in them and then selects those spaces. This is be more challenging since you have to somehow determine how many spaces your hashes can have or you need a particular way to tell the computer when you are done with your hash. You then can substitute those particular spaces with something else.
Having those RegEx’s you can have a simple script that runs through the RegEx’s and checks for the level location.
It seems as if what you want is REALLY REALLY difficult because you need a way to know when your tag is done. I would not like to say that you want is impossible because RegEx is its own programming language with experts there. But I would recommend you to try something other than spaces. I have seen people using comas to distinguish when the tag is done, like the following
#This is, #an, #example
That way you can have the program know when the tag is done. If you think that you like spaces, then comas are the way to go. Of course, that complicates the RegEx expression even more, but I think that someone can come up with something to help you.
Also, you will have to make sure that you are ONLY placing the tags at the end of the line. If you add any other text at the end of the line, the RegEx will fail. Hope this helps.
Thanks so much for everyone’s input! I greatly appreciate it, and I’m sorry for my late reply… Basically, I’m imagining two scripts that would toggle between two functions:
Find & Replace: # ‘s - with nothing ; :’ s - with nothing ; and _ 's with a space;
Undo the Find & Replace functions above;
That’s it!
So, how’d you suggest I set up scripts to accomplish this?
Fair enough. In this instance, I use TaskPaper as a way to organize a set of tags that I use when annotating PDF files – and then I use the same TaskPaper file in tandem with OmniOutliner to render (further organize) those annotations further. So, I used the normal syntax in TaskPaper (with hashtags and underscores) when copying and pasting tags – which is also why I keep asking if it’s possible to Copy multiple selected items? (or select & copy discontiguous text) !
But in order to use TaskPaper files with OmniOutliner, I need to first Find & Replace: # ‘s - with nothing ; : ’ s - with nothing ; and _ 's with a space. Because I sometimes go back to the original file, and use it to do more annotations, I also want the option to undo those Find & Replace functions. Does this make sense?
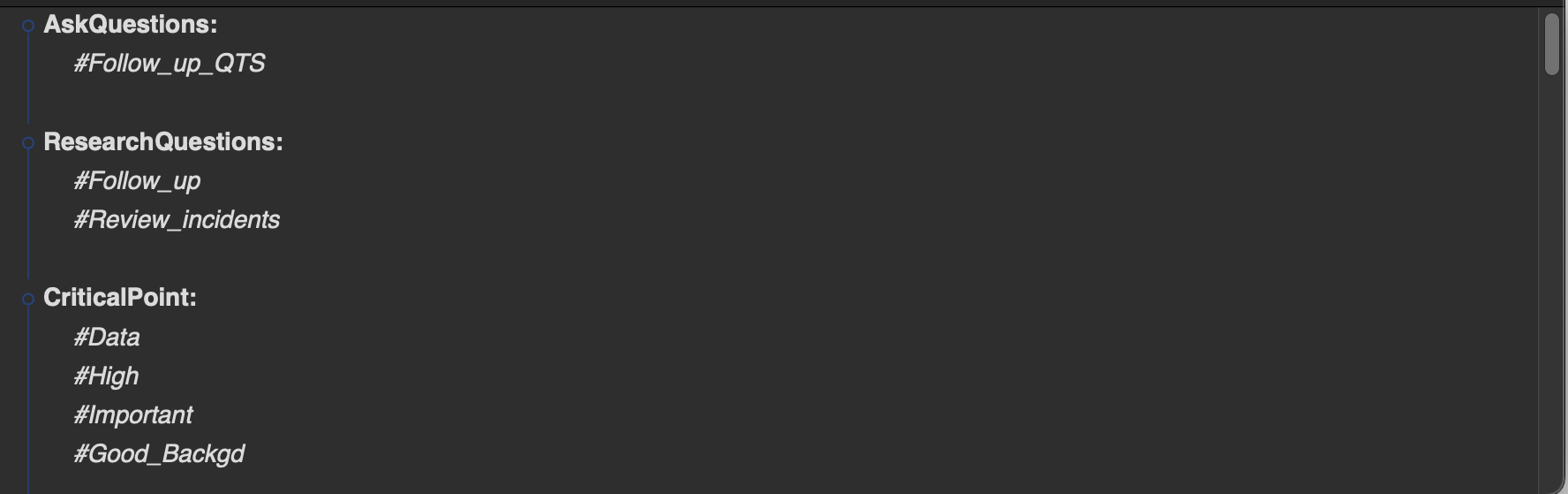
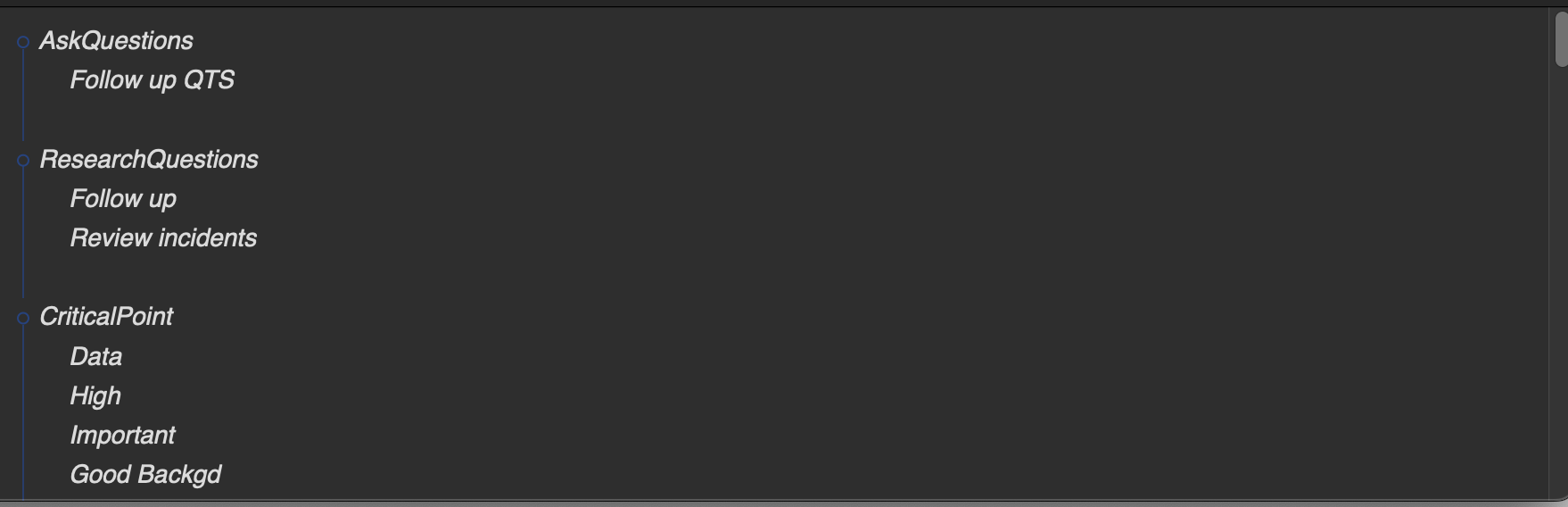
Of course. Here’s a section where the hashtags, colons, and underscores are intact…
Oh wow. Thank you so much for this! I’m excited to give it a try…
I’ve used Keyboard Maestro periodically, and would certainly be happy to use that with your script. How would one do so?
Also, do you think there’s a way to use Keyboard Maestro to select & copy discontiguous text, as I outlined in this post: Copy multiple selected items?
Out of time now, but might take a look at the solution suggested by Jesse over the weekend.
I think it is a generic solution into which you can plug some problem-specific script, so you would probably need to show me a couple of use-cases with before and after examples.
```
Preferably as text pasted here between triple backticks,
rather than graphic images, so that I can copy them for testing.
```
Something like a pair of macros:
toggle a @selected tag on and off in selected lines.
apply some other change to all lines that are tagged as @selected, perhaps clearing that tag once the changes have been made.
i.e. you would need to show me before and after examples of a couple of instances of what other change might be.
Unless you just want to copy the text of all items marked with that tag ?