- Added Bike Markdown format (.bikemd)
- Added Edit > Copy > Copy as Bike Markdown
- Added to/from Markdown API
- Improved pasting links
Download:
Download:
I’ve had some new ideas on “markdown” and think I have a pretty good solution in this release.
First, I’ve long delayed markdown support in Bike because there’s no good mapping between Bike and the full markdown spec. Seems like it should be possible, but it’s a mess of corner cases that don’t quite work. And without a full mapping it means Bike will either loose Markdown structure or its own outline structure when editing and saving Markdown.
This was frustrating, because there is a nice clean mapping between large parts of Bike and Markdown. Solution … why didn’t I think of this sooner … “Bike Markdown”.
It’s a clean and simple mapping from Bike’s data model to something that is “mostly” markdown.
Features:
Compared to standard markdown some differences are:
So now if you open a .md file in Bike… you’ll just get the plain text of that file, because Bike doesn’t understand full markdown… on the other hand if you open a .bikemd file then the markdown will be read into a Bike outline structure in a consistent way, and also written out in a consistent way.
Open to feedback on how to improve, or just bug reports.
Well shoot… in all the excitement I uploaded wrong Bike 246 … without markdown support. I’ve just fixed that download… if you click the download link above you should now get correct version.
Thanks a million for these new options! I’ve been waiting for this for soooooo long. Glad it’s now a part of Bike. Copy as Bike Markdown makes the transfer from outline to MD document in iA Writer or other apps a breeze … before it was a chore. I will now be using Bike a LOT more than previously. Really appreciate this.
This is great – I like the encoding of increasingly nested Bike heading type rows in terms of increasing length of ### markup, and the inclusion of inline markup like <mark> <sub> <sup> etc.
Is there an asymmetry in this draft’s implementation of strikethrough ?
<s> </s>bikemd, and Copy As), we seem to be getting only a single tilde at each end of the This is great stuff! The fact that Bike outlines are now unlocked as markdown on iOS is a huge deal, especially since all the common stuff - lists, tasks headings, basic formatting, translates very nicely into most markdown editors.
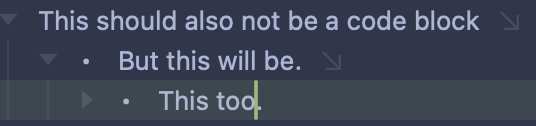
One thing I notice, in addition to @complexpoint ‘s comment on strikethru is that when I use a code block row type, the .bikemd file will output:
```This is a code block
instead of
```
This is a code block
```
Because there’s no closing ``` it means that the remainder of the text in the document will be interpreted as a code block.
Conversely, a ‘proper’ markdown codeblock will be read by Bike as Body text wrapped between two Code block row types:
func sayHello() -> String {
return(hello + boinkers)
}
Not sure what the correct approach here is. I think this is an acceptable limitation.
I’m using swift-markdown package for parse/write of the inline elements, and that seems to be its default behavior. I’m not sure if there’s a knob to change, I don’t see yet, but seems there must be some way.
Hum, yeah code blocks are definitely a problem. I will change the ``` marker syntax or figure a way to add proper start/end wrapping.
I’m also now realizing that it wouldn’t be too hard to give the Markdown format full parity with Bike’s html format using custom inline and row attributes. The problem is syntax. Using swift-markdown I get custom inline attributes for free using this syntax:
Use swift-markdown ^[custom](attributes) inline attribute syntax
Unfortunately that seems similar, but a bit different to the syntax that pandoc uses [text]{attributes}. Any thoughts on why they went with this different syntax?
What should Bike use? Another option is maybe to use inline <span attributes>text</span>?
*scratches head*
Wouldn’t that make the .bikemd file parseable pretty much to just Bike?
I don’t think so, these ideas are already part of important markdown processing tools such as pandoc.
Also, this is just for custom attributes, for standard attributes such as bold, italic, links, heading, etc you get standard markdown. The problem is that Bike’s data model allows you to associate arbitrary keys/values with any row and with any span of text.
What I’m saying is that the markdown format can also store those custom attributes (which at the moment you can only add via programming API) too, and thus give Bike’s markdown format full parity with the HTML format.
As an example of what it would look like using pandoc syntax:
*normal emphasis syntax* world.
- one
- [normal link](www.hogbaysoftware.com)
- [requires custom attributes]{favorite=pizza}
And this row has row level custom attributes {#myid}
So first you only get these custom attributes if you construct/configure your outline in a way that requires them. And second they are standards of sorts used in other places. Though this is also the reasons why I went with HTML for Bike’s first format, there isn’t really many hard and fast standards for extending markdown.
Originally I suggested ^[custom](attributes) syntax because that’s what the swift-markdown parser supported, so I thought it was some sort of “standard”. After searching around, I don’t see much use of it, but the pandoc syntax (or at least pandoc in general) does seem quite often used. So I think that’s what I’ll go with.
Feedback welcome ![]() Still trying to figure this all out.
Still trying to figure this all out.
Sounds good – the Pandoc approach does seem sensible middle ground,
and well plumbed into many other formats …
Here’s a question:
Should I encode body row as list items (with a special marker) when they are indented? Otherwise markdown system sees them as code blocks. I guess I would use the + for this. And when parsing would detect that marker and parse as a body type row, not an unordered list. I think this probably makes sense, but feedback welcome.
I’m trying to handle this case in Bike:
one
two
And proposing it is encoded as:
(normal Bike unordered rows would be encoded using - marker)
+ one
+ two
I think I follow, but there’s still a lot I don’t understand about what the final .bikemd file would show-this is where it gets a little too technical for me.
I guess what I was going for is to avoid having the .bikemd be ‘polluted’ by data that doesn’t make sense when you’re reading it in other plain-text/md editors. I’d gladly sacrifice some data fidelity to gain interoperability with other platforms, particularly iOS/iPadOS, without having to resort to document conversion first; but I also understand others might want more granular parity.
I suppose you could, but then again, something like this will also be rendered as a code block. Not sure it makes sense to handle all these cases?
It’s also a hard to track moving target here… very much still a work in progress.
I think there are a few use cases, and this is a very important one that I think will work well.
The thing to know is “all” these additions of inline attribute syntax, block attribute syntax, etc … they only “activate” when you use them. Outlines that just use standard markdown formatting won’t see them at all.
One big change that I’m making for the next release is I will always encode your full outline as a markdown list. This simplifies many things and removes some file format bugs that made it impossible to save all the outline state correctly.
So in the next version every non empty line will start with a +, -, or number. This makes an easy and direct mapping between Bike and Markdown. It also gets rid of all the (looks like code to markdown) syntax problems.
I liked the flattening of header idea, but it became too complex, and introduced some cases were outline information would be lost on save… (the last header in your outline would grab all trailing children no matter indentation level)
Export to flattened Markdown document is a future task sometime down the road.
Last, I expect an optional “front matter” block that can be used to configure what custom attributes Bike saves in bikemd. For example I don’t expect it to save all ids or created and modified information by default. But if you do want to also save that using custom attributes, you’ll be able to turn that on by adding a front matter block saying you want it.
Hope that makes some sense.
It does! And I hope you know you’re headed for Logseq MD territory, so expect an influx of users! ![]()
Oh, thanks for reference, I’ve played with Logseq, but never really thought about file format. They seem to have a good syntax for codeblocks! I’ll see if I can use that too.
Thanks @jessegrosjean - the new Markdown support will be very very helpful!
A few quick notes from testing:
Currently, saving as .bikemd works fine, but .bikemd files are only recognized on macOS - no Markdown/plaintext editor can open them on iOS.
Manually changing .bikemd → .md allows editing on iOS, but Bike then no longer recognizes the file as a valid .bikemd.
A possible workaround could be using frontmatter metadata to tell Bike it’s a .bikemd file, regardless of extension.
Would love to hear your thoughts on whether this approach could work or if another solution is planned.
EDIT:
I did not notice that Bike had a specific setting for the extension, so after changing the extension to .mdin Bike’s settings, I can now open the file on iOS.
EDIT 2:
Changing the extension to .md through Bike’s setting breaks the formatting in Bike, so I guess only solution is to stick with .bikemd for now
Unfortunately that seems similar, but a bit different to the syntax that pandoc uses [text]{attributes}. Any thoughts on why they went with this different syntax?
What should Bike use? Another option is maybe to use inline text?
Here is where the mess really starts. Of course, if you choose one ‘flavour’ of markdown, the other people that uses other flavours will be unhappy.
Leaving apart the markdown mess and the lack of sanity in every attempt to make a “new flavour”, I would suggest to follow the specification of pandoc.
The majority of the markdown editors follows the so-called mmd (or MultiMarkdown), because the compiler is “complete” and small (< 2mb), so they can embeed it and export the result for a lot of formats. But the point is that they use .mmd as a background to offer export options (epub, opml, html) for fairly simple documents. The huge downside of mmd is that they treat all apparatus in the same way, for example: footnotes and citation are virtually put in the same way:
Here a citation [see][@citekey]
[@citekey]: Bibliography
Here a footnote[^1]
[^1]: Footnote
The support for anything extra than the very basic markdown is rudimentary and not easy to automate. Basically, everything needs to be declared verbatim. Otherwise, you do not get the appropriated final result.
If we think in terms of processing markdown, as I suggested, then following the pandoc flavour will enable much more customization and easy to use for different workflows. Because, for sure, pandoc is years-light above any other markdown compiler, it is not even comparable.
EDIT: It is important to notice that cross-references and other things more advanced are not well structured in other markdown flavours as it is in pandoc. To be honest, pandoc take a lot of inpiration from .rst do develop the extra attribute declaration. In this case, I think that pandoc is the winner again (by huge margin).
Last, I expect an optional “front matter” block that can be used to configure what custom attributes Bike saves in bikemd. For example I don’t expect it to save all ids or created and modified information by default. But if you do want to also save that using custom attributes, you’ll be able to turn that on by adding a front matter block saying you want it.
This would be a killer feature! I give 10+ upvotes for this!